10 billion person records, check. 100 billion transaction records, check. 10k updates and searches per second, check.
SearchCluster scales both in terms of how much data can be stored, as well as how many API requests can be processed.
The architecture of SearchCluster has unlimited scalability built-in from the start. Active production installations for mission-critical use cases with hundreds of millions of complex person records are confirmed for the solution over the years.
Storage layer
OpenSearch (formerly Elasticsearch) manages the data with redundancy and limitless scalability. Each data item is stored multiple times, on separate underlying hardware. Apache Lucene is the technology underneath OpenSearch.
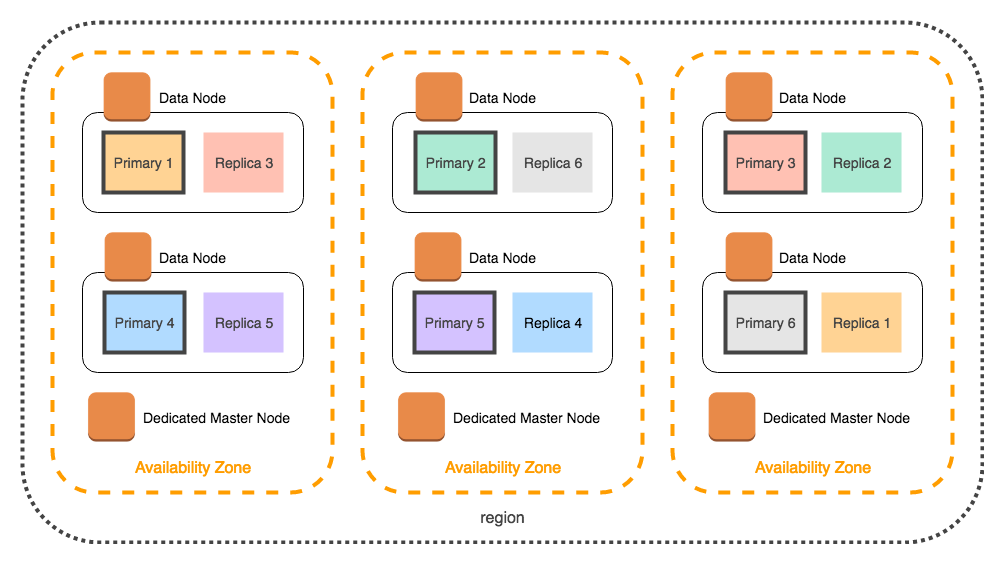
This clever yet simple design makes it a breeze to store many more people records than there are people living on this planet.
Matching layer
The Optimaize record matching layer is a stateless application, and is multiplied many times throughout the clusters. These worker nodes handle the detailed record comparisons and filtering after the Opensearch queries delivered possible match candidates in the recall step. As this component is stateless and can work fully independently, it is scalable infinitely.
Concurrent searches
As each data item is stored multiple times, concurrent searches can run on different hardware. This again allows for deep scaling to run thousands of concurrent searches.
Concurrent record updates
Inserts, updates and deletes write through to all data nodes, and all replicas, and are visible within 1 second.
<- Back to SearchCluster page.